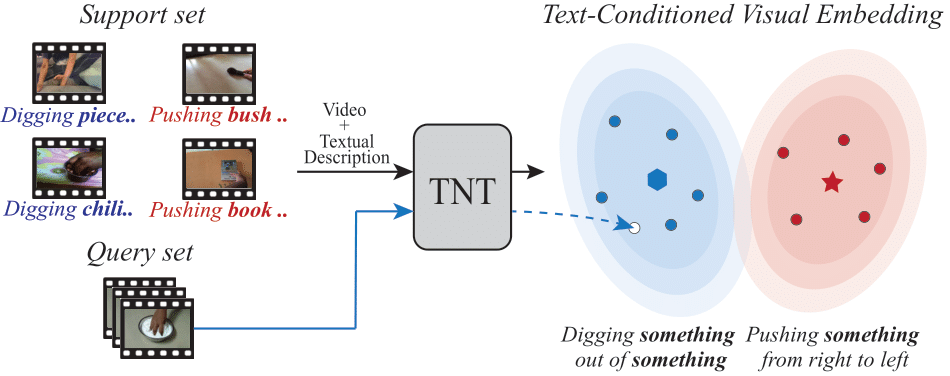
Humans use language to guide their learning process [14]. For instance, when teaching how to prepare a cooking recipe, visual samples are often accompanied by detailed or rich language-based instructions (e.g., “Place aubergine onto pan”), which are fine-grained and correlated with the visual content. These instructions are a primary cause of the human ability to quickly learn from few examples because they help to transfer learning among tasks, disambiguate and correct error sources [14]. However, modern deep learning approaches in action recognition [5, 11, 23] have mainly focused on a large amount of labeled visual data ignoring the textual descriptions that are usually included along with the videos [5, 7]. These limitations have motivated an increasing interest in Few-Shot Learning (FSL) [24], which consists of learning novel concepts from few labeled instances.
Current approaches in few-shot video classification mostly focus on effectively exploiting the temporal dimension in videos to improve learning under low data regimes. However, most works have largely ignored that videos are often accompanied by rich textual descriptions that can also be an essential source of information to handle few-shot recognition cases. We propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Furthermore, our model follows a transductive setting to improve the task-adaptation ability of the model by using the support textual descriptions and query instances to update a set of class prototypes. Our model achieves state-of-the-art performance on four challenging benchmarks commonly used to evaluate few-shot video action classification models.
Related Work
Few-Shot Learning
It is possible to identify two main groups in the FSL literature: (i) gradient-based methods and (ii) metric learning based methods. Gradient-based methods focus on learning a good parameter initialization that facilitates model adaptation by few-shot fine-tuning [3, 16, 18]. On the other hand, metric-based methods aim to learn or design better metrics for determining similarity of input samples in the semantic embedding space [9, 17, 20, 21, 22]. More recently, affine conditional layers are added to the feature extraction backbone in [1, 19] as extension to the conditional neural process framework [4] with the goal of effective task-adaptation. In this work, we extend this framework [4] differently from [1, 19] by adapting the feature extractor and updating the class representations based on the support textual descriptions and query instances. Our goal is to influence the visual backbone with the structured knowledge captured by pre-trained language models.
Induction vs Transduction in FSL
Regarding the inference setup, there are two types of approaches: inductive and transductive FSL. We are motivated by recent work following the transductive setting [8, 12, 13, 16], where the unlabeled query data is exploited to further refine the few-shot classifier. For instance, [12] proposes a prototype rectification approach by label propagation. Departing from previous work, our model proposes a novel transductive approach that takes advantage of the support textual descriptions to augment the support videos with the unlabeled instances, leveraging the cross-attention approach.
Few-Shot Video Classification
There are few works to tackle this problem in video domain. However, most of them are focused only on better exploiting visual or temporal information from videos [2, 10, 15, 25, 26, 27, 28, 29]. Although tackling important aspects in video data modeling, none of the previous works offer solutions to the semantic gap between the few-shot samples and the nuanced and complex concepts needed for video representation learning. We aim to bridge this gap by using textual descriptions as privileged information to contextualize the video feature encoder in conjunction with a classification approach based on class prototypes acting under a transductive inference scheme.
Our approach
Problem Definition
FSL aims to obtain a model that can generalize well to novel classes with few support instances. Therefore, we follow the standard FSL setting [20, 22], wherein a trained model fθ is evaluated on a significant number of N−way K−shot tasks sampled from a meta-test set Dtest. These tasks consist of N novel categories, from which K samples are sampled to form support set S, where K is a small integer, typically, 1 or 5. The support set S is used as a proxy to classify the B unlabeled instances from the query set Q. The parameters θ of the model f are trained on a meta-training set Dtrain, by applying the episodic training strategy [22]. This is, N−way K−shot classification tasks are simulated by sampling from Dtrain during meta-training. Q is sampled from the same N categories in such a way that the samples in Q are non-overlapping with S.
TNT Model
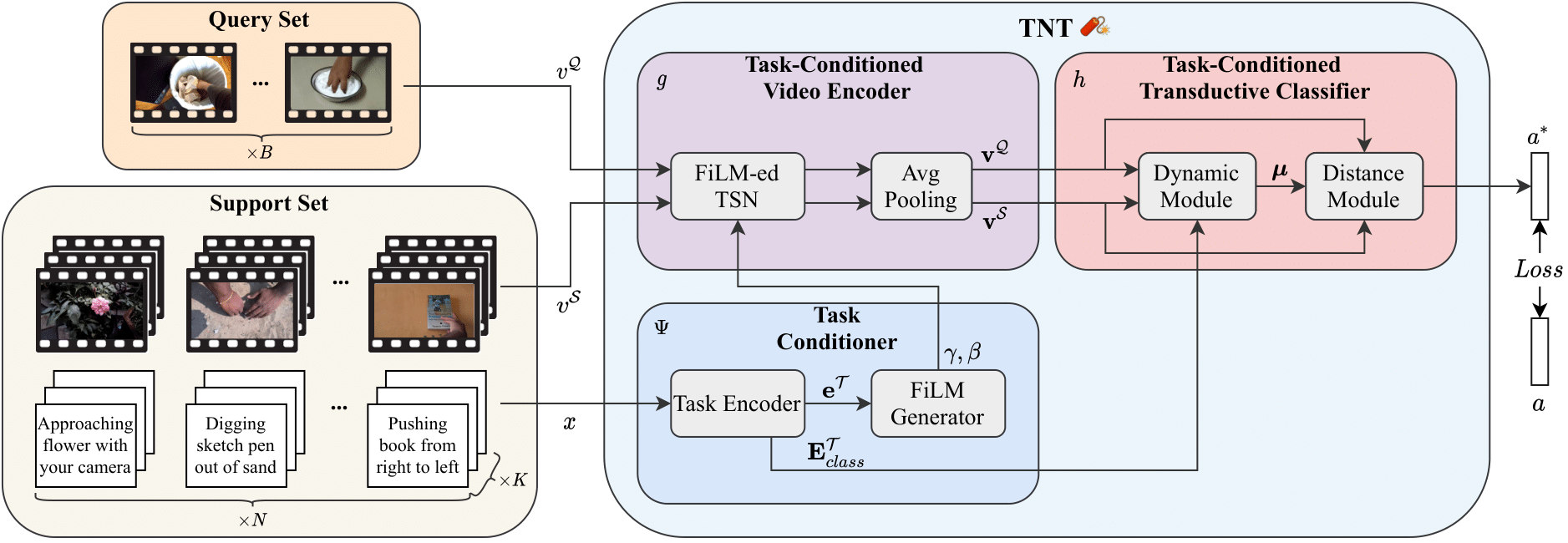
We strive for action classification in videos within a low-data setting by means of (1) the rich semantic information of textual action descriptions and (2) exploiting the unlabeled samples at test time. Our Text-Conditioned Networks with Transductive Inference (TNT) is a text-conditioned neural network designed to be flexible and adaptive to novel action labels. Taking inspiration from [1, 19], TNT is composed by three modules: (1) Task-Conditioned Video Encoder g; (2) Task Conditioner Ψ; and (3) Task-Conditioned Transductive Classifier h.
Task-Conditioned Video Encoder
This module g transforms the lower-level visual information of each video v into a more compact and meaningful representation v. To handle novel action classes at test time, it is essential to provide g with a flexible adaptation mechanism that selectively focuses and/or disregards the latent information of its internal representation across different episodes. To achieve this, we employ the TSN video architecture with a ResNet backbone that is enhanced by adding Feature-wise Linear Modulation (FiLM) layers after the BatchNorm layer of each ResNet block. FiLM layers adapt the internal representation vi at the ith block of g via an affine transformation FiLM(vi;γi,βi) = γivi + βi where γi and βi are the modulation parameters generated by the Task Conditioner module.
Task Conditioner
The Task Conditioner Ψ is an essential part of our approach that provides high adaptability to our model. Specifically, it computes conditioning signals that modulate the Task-Conditioned Video Encoder g and the Task-Conditioned Transductive Classifier h based on the textual action descriptions of a set of support instances S. Furthermore, the Task Conditioner subsumes two components:
Task Encoder
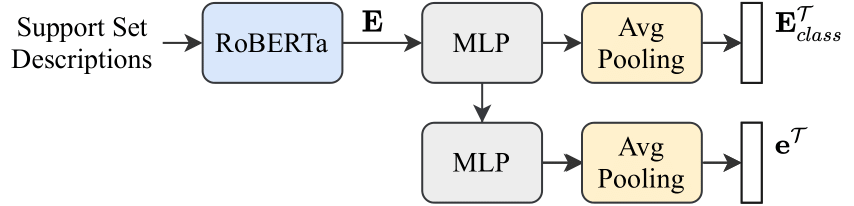
This module generates the conditioning signals: (1) the task embedding eT to tune the Task-Conditioned Video Encoder g, and (2) the semantic class embedding ETclass used to tune the Task-Conditioned Transductive Classifier, given the textual action description x in the support set S. Using RoBERTa, we compute the sample-level text embedding E of each x. These text representations are projected first through linear layer and average pooled along the number of shots K, resulting in the class embedding. Additionally, E is linearly projected a second time to obtain the task embedding.
FiLM Generator
It generates the set of affine parameters γi, βi for every stage i of g to effectively modulate our Task-Conditioned Video Encoder given the task embedding eT. In practice, we tune the MLP modules and the FiLM generator parameters in a subsequent training stage after fixing g.
Task-Conditioned Transductive Classifier
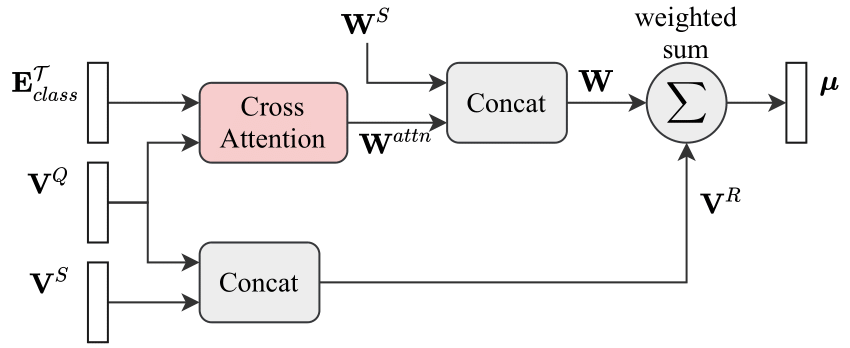
This module h follows a metric learning approach to classify the unlabeled samples of Q by matching them to the nearest class prototype. To obtain the class prototypes, a straightforward approach is to compute a class-wise average by considering the K-examples in the support set S [1, 4, 33]. However, due to the data scarcity, these prototypes are usually biased. To alleviate this problem, we use a transductive classifier that leverages the unlabeled samples to improve the class prototypes based on the semantic class embedding ETclass.
Results
We compare the performance of our full TNT model against three state-of-the-art methods for few-shot video classification, namely TAM, CMN and ARN. Additionally, we compare our method against other baseline methods that are popular in the literature about FSL: Matching Networks, MAML, and TSN/TRN++. To make the comparison fairer, we propose a transductive baseline named TSN++ transductive. We achieve state-of-the-art-results in 7 out of 8 standard benchmark metrics across the four tested datasets. Notably, our model achieves outstanding results in both families of datasets: (1) those with rich and detailed textual descriptions of actions per video: Epic-Kitchens, Something-Something V2, and (2) those with short class-level descriptions: UCF-101 and Kinetics. Likewise, our model exceeds the TSN++ transductive, which shows the relevance of using the textual descriptions to modulate the network and make a transductive inference.
We evaluate our model trained on SS-100 in the 5-way, 5-shot task with B = 50, increasing the value of B from 5 to 100. Model performance increases until the number of query samples B = 50 after which it remains almost constant. We hypothesize that this is due to a saturation point on the amount of extra information that can be extracted from query samples.
We also conduct qualitative evaluations to demonstrate how our model works and the relevance of using textual descriptions to modulate the visual feature encoder and perform a transductive inference.
Action label: pouring something out of something
Video

w/ Film Layer

w/o Film Layer

References
1. Peyman Bateni, Raghav Goyal, Vaden Masrani, Frank Wood, and Leonid Sigal. Improved few-shot visual classification. In IEEE Conf. Comput. Vis. Pattern Recog., June 2020. ↩
2. Kaidi Cao, Jingwei Ji, Zhangjie Cao, Chien-Yi Chang, and Juan Carlos Niebles. Few-shot video classification via temporal alignment. In IEEE Conf. Comput. Vis. Pattern Recog., June 2020. ↩
3. Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. volume 70 of Proceedings of Machine Learning Research, pages 1126–1135, International Convention Centre, Sydney, Australia, 06–11 Aug 2017. PMLR. ↩
4. Marta Garnelo, Dan Rosenbaum, Christopher Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo Rezende, and S. M. Ali Eslami. Conditional neural processes. In Int. Conf. Machine learning, volume 80, pages 1704–1713. PMLR, 2018. ↩
5. R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman. Video action transformer network.. IEEE Conf. Comput. Vis. Pattern Recog., 2019. ↩
6. J. Ji, S. Buch, JC. Niebles, and A. Soto. End-to-end joint semantic segmentation of actors and actions in video. In Eur. Conf. Comput. Vis., 2018. ↩
7. Will Kay, João Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset. CoRR, abs/1705.06950, 2017. ↩
8. Jongmin Kim, Taesup Kim, Sungwoong Kim, and Chang D. Yoo. Edge-labeling graph neural network for few-shot learning. 2019. ↩
9. Gregory Koch. Siamese neural networks for one-shot image recognition. In Int. Conf. Machine learning, 2015. ↩
10. Sai Kumar Dwivedi, Vikram Gupta, Rahul Mitra, Shuaib Ahmed, and Arjun Jain. Protogan: Towards few shot learning for action recognition. In Int. Conf. Comput. Vis. Worksh., pages 0–0, 2019. ↩
11. Ji Lin, Chuang Gan and Song Han. Tsm: Temporal shift module for efficient video understanding. In Int. Conf. Comput. Vis., October 2019. ↩
12. Jinlu Liu, Liang Song, and Yongqiang Qin. Prototype rectification for few-shot learning. In Eur. Conf. Comput. Vis., August 2020. ↩
13. Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sungju Hwang, and Yi Yang. Learning to propagate labels: Transductive propagation network for few-shot learning. In Int. Conf. Learn. Represent., 2019. ↩
14. Gary Lupyan and Benjamin Bergen. How language programs the mind. volume 70 of Topics in Cognitive Science, 8(2):408–424, 2016. doi: https://doi.org/10.1111/tops. ↩
15. Ashish Mishra, Vinay Kumar Verma, M Shiva Krishna Reddy, Arulkumar S, Piyush Rai, and Anurag Mittal. A generative approach to zero-shot and few-shot action recognition. In 2018 IEEE Winter Conference on Applications of Computer Vision, pages 372–380, Los Alamitos, CA, USA, mar 2018. IEEE Computer Society. doi: 10.1109/WACV.2018.00047. ↩
16. Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms, 2018. ↩
17. Hang Qi, Matthew Brown, and David G Lowe. Low-shot learning with imprinted weights. In IEEE Conf. Comput. Vis. Pattern Recog., pages 5822–5830, 2018. ↩
18. Aravind Rajeswaran, Chelsea Finn, Sham M Kakade, and Sergey Levine. Meta-Learning with implicit gradients. In Adv. Neural Inform. Process. Syst., pages 113–124, 2019. ↩
19. James Requeima, Jonathan Gordon, John Bronskill, Sebastian Nowozin, and Richard E Turner. Fast and flexible multi-task classification using conditional neural adaptive processes.. In Adv. Neural Inform. Process. Syst., 2019. ↩
20. Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. Adv. Neural Inform. Process. Syst., pages 4077–4087. Curran Associates, Inc., 2017. ↩
21. Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip H. S. Torr, and Timothy M. Hospedales. Learning to compare: Relation network for few-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1199–1208, 2018. doi: 10.1109/CVPR.2018.00131. ↩
22. Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. In Adv. Neural Inform. Process. Syst., pages 3630–3638, 2016. ↩
23. Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell., 41(11):2740–2755, 2019. ↩
24. Yaqing Wang, Quanming Yao, James T. Kwok, and Lionel M. Ni. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv., 53(3), June 2020. ISSN 0360-0300. doi: 10.1145/3386252. ↩
25. Yongqin Xian, Bruno Korbar, M. Douze, B. Schiele, Zeynep Akata, and L. Torresani. Generalized many-way few-shot video classification. In Eur. Conf. Comput. Vis. Worksh., 2020. ↩
26. Baohan Xu, Hao Ye, Yingbin Zheng, Heng Wang, Tianyu Luwang, and Yu-Gang Jiang. Dense dilated network for few shot action recognition. ICMR18, page 379–387, New York, NY, USA, 2018. Association for Computing Machinery. ISBN 9781450350464. doi: 10.1145/3206025.3206028. ↩
27. Hongguang Zhang, Li Zhang, Xiaojuan Qi, Hongdong Li, Philip H. S. Torr, and Piotr Koniusz. Few-shot action recognition with permutation-invariant attention. In Eur. Conf. Comput. Vis., 2020. ↩
28. Linchao Zhu and Yi Yang. Compound memory networks for few-shot video classification. In Eur. Conf. Comput. Vis., September 2018. doi: 10.1007/978-3-030-01234-2_46. ↩
29. Xiatian Zhu, Antoine Toisoul, Juan-Manuel Perez-Rua, Li Zhang, Brais Martinez, and Tao Xiang. Few-shot action recognition with prototype-centered attentive learning. arXiv preprint arXiv:2101.08085, 2021. ↩